Building a Veracity Module - Part 3
So how does the Wiki module work, anyway? Pretty much the way you’d expect a web app to work.
- The Wiki form is displayed (and maybe pre-populated with the page’s title and text)
- You edit the title and text, and submit
- We bundle those fields up into a JSON package
- And send that along to the server-side Wiki code
- That code either
- Updates the page if it already existed, or
- Creates a new page
- On success, we reload the wiki page
All of the Veracity-specific stuff happens on the server side.
Retrieving a Page
We retrieve the existing page in the GET
/wiki/pages/<pagename>.json route (mentioned in Part 2 the other day). Normally (q.v.), that’s as simple as:
var db = new zingdb(request.repo, sg.dagnum.WIKI);
var w = vv.where( { "title": request.pagename } );
var recs = db.query('page', ['text','title','recid'], w);
return( recs[0] );
Which translates to “Open the wiki database, find any records matching
our pagename, grab their text, title and recid fields, and
return the first one.” We can get away with this since our database
template requires the pagename to be unique.
A JSON representation of that object is returned (you’ll also see some caching logic in there, but that’s strictly a performance measure, ignorant of the Wiki data).
Creating and Updating
Updates work like so:
var csid = newrec._csid || null;
delete newrec._csid;
ztx = db.begin_tx(csid, request.headers.From);
if (newrec.recid)
rec = ztx.open_record('page', newrec.recid);
else
{
rec = ztx.new_record('page');
newrec.recid = rec.recid;
}
rec.title = newrec.title;
rec.text = newrec.text;
vv.txcommit(ztx);
- Get the changeset ID (if any) that this update is based on (more on this in a moment)
- Start a new transaction
- Do we already have a record ID? If so, this is an update. Open that record.
- If not, this is a new page. Create a record.
- Set the record’s title and text to those passed in from the form.
- Commit.
We then return OK to our caller, the page is reloaded, the circle of
life continues.
Merges
So what’s up with the changeset ID, and why did we have to say “normally” before?
It’s possible that, by the time you’re saving your changes, someone else has updated the same page. Or maybe your changes are in a nice straight line locally, but a push or pull brings in someone else’s previously-unknown edits. Veracity doesn’t get to throw up its hands and fail. It needs to merge.
And to merge your changes and mine, it needs to know where we each started from. That’s why we pass the changeset IDs around; it tells Veracity “here’s my latest changes, and the last version I knew of was rev 1234”. Later, when Veracity merges that with someone else’s updates, it knows those were based on rev 1235; it finds a common ancestor, does a smart 3-way merge, and all’s well. Almost always.
“Almost always” is not “absolutely always”, though.
What if we both started with:
line 1
line 2
as our text. Then I edited it to read:
line 1
line one and a half
line 2
while off on your machine, you edited it to:
line 1
line 1.5
line 2
Then you pull my changes. Now what? Should your changes be thrown away? Should mine? Should both lines be included? Any of these are possible, but in the template we have to pick one.
The “merge strategy” the Wiki template uses is to concatenate our two texts, and let a human being sort things out. Elsewhere (e.g. in the scrum module) we use all sorts of other strategies, including automatically changing the ID of a work item when it conflicts with one created elsewhere). Since Wiki text is intended for human usage only, and is completely arbitrary, there’s no sense trying to guess the “appropriate” conflict resolution between two edits.
So in this situation, anyone opening the merged page will see:
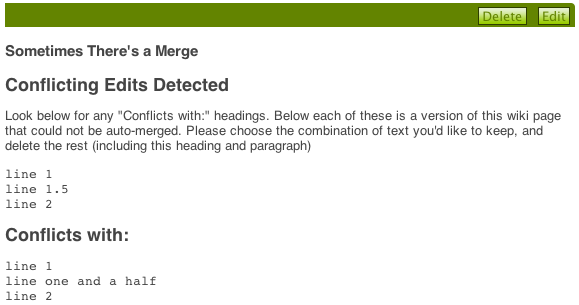
Edit that as needed, and all’s well with the world again.
Next (and hopefully final) time: plugging into Veracity’s activity stream and cache.